

キーワード出現率を無料で調べたい

キーワード出現率チェックって必要?

キーワード出現率チェックは、SEOの重要な確認項目です。
無料で使えるキーワード出現率チェックサイトを紹介します。
なぜ、キーワード出現率を調べる必要があるのでしょうか?
その理由を説明していきます。
最後に、自作したチェックツールについて紹介しています。
ぜひ参考にしてください。

キーワード出現率の重要性を知って、
あなたも自分の記事をチェックしましょう。

この記事を書いた人

ゆめ ただ
グログ歴 5年目。
普通のビジネスマンとして働きながらFIREを目指す。
独学でゼロからブログを立ち上げる。
Dockerのローカル仮想環境を作りLinux環境も触るように。
4年目でSEO検定1級に合格し地道にスキルアップ。
次はWordPress以外のCMSに手を出そうか悩み中。
キーワード出現率チェックが必要な理由
キーワード出現率のチェックは、SEO対策として必須です。
上位表示されている記事のキーワード出現率を調べて、それに近づけていく方法が有効と言われています。
では、なぜキーワード出現率を毎回チェックするのでしょうか?
なぜなら、キーワードによって「上位表示されている記事の出現率が異なる」からです。
キーワード毎に、上位表示されている記事のキーワード出現率をチェックして、そこに寄せていきましょう。

ここがポイント
・キーワードによって、記事内のキーワード出現率が異なる。
・上位表示されている記事のキーワード出現率をチェックして、それに寄せていくコトがSEO対策の1つとなる。
キーワード出現率がチェックできる無料サイト
キーワード出現率がチェックできる無料サイトをまとめました。
ohotsuku
ohotsuku:無料のキーワード出現率チェックサイト。
URLを指定して、キーワードと出現目標率を指定。
あといくつキーワードを出現させれば目標に達成するかも教えてくれます。
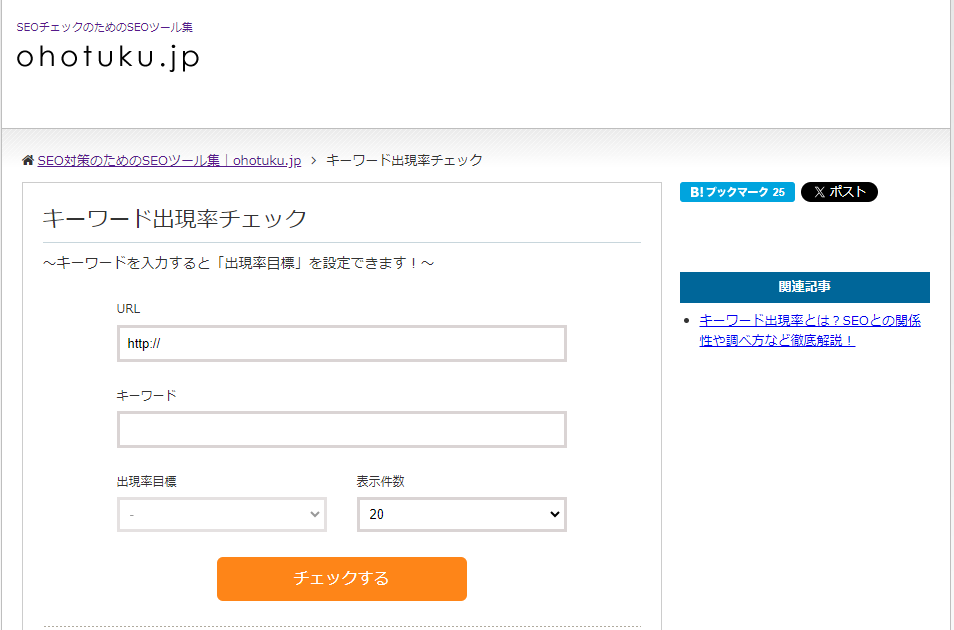
無料で便利なサイトです。
追加したい機能
キーワードが1語しか指定できないので、複数キーワード調べたい場合は指定キーワードを変えて再検索する必要がある。
1度に3語まで指定したい。
ファンキーレイティング
ファンキーレイティング:無料のキーワード出現率チェックサイト。
URLもしくはテキストファイルを指定して、キーワードと出現目標率を指定。
3語までキーワードを指定可能。あと何語出現させれば目標に達成するかも教えてくれます。
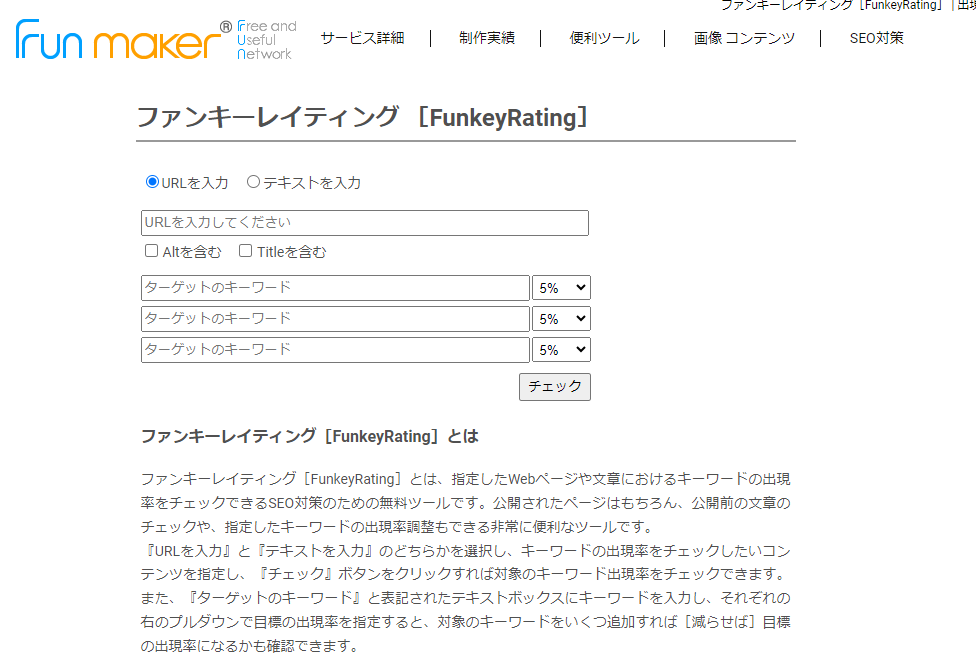
3キーワードまで指定でき、出現目標率も設定可能。
改善したいポイント
検索キーワードが複合キーワードの場合、検索できない場合がある。
例1:「ラッコキーワード」->「ラッコ」+「キーワード」に分かれてしまうため検索できない。
例2:「検索ボリューム」->「検索」+「ボリューム」に分かれてしまうため検索できない。
複合キーワードに対応したい。
自作キーワード出現率チェックプログラムの仕様
キーワード出現率チェック無料サイトと,、自作ツールで実現したいことを比較表にまとめました。
\無料キーワード出現率チェックサイトと自作ツールの比較表/
| キーワード出現率 チェック方法 | 指定できるキーワード数 | 総単語数 | 総文字数 | URL指定 | ファイル入力 | 追加・改善ポイント |
|---|---|---|---|---|---|---|
| ohotsuku |
 1語のみ
|
 対応
|
 非対応
|
対応
|
非対応
|
キーワードが
1語しか指定できない |
| ファンキーレイティング |
3語まで指定可
|
対応
|
非対応
|
対応
|
対応
|
複合キーワードが
検索できない 例:ラッコキーワード |
| 自作プログラム |
3語まで対応
|
対応
|
対応
|
非対応
|
対応
|
3語対応
複合キーワード対応 |
キーワード出現率チェック無料サイトの改善したいポイントを、自作ツールで実現することにしました。
自作キーワード出現率チェックプログラムの仕様
- キーワードは3語まで指定可能
- 複合キーワードもチェック可能
- 単語総数、総文字数も計算する
- 入力はファイルのみ、URL指定は非対応
- CSVファイルに出力できる
- C言語で作成、Windowsのコマンドラインで動作する

自作ツールの結果を評価
実際の記事を使って、自作ツールを評価してみました。
結果は次の通り。
まずまずの結果が得られています。
3語までキーワード指定ができ、複合キーワードを指定しても出現率を計算してくれます。
\キーワード出現率チェック無料サイトと自作ツールの結果比較/
| キーワード出現率チェック方法 | 単語総数 | キーワード出現数 | 出現率 |
|---|---|---|---|
| ohotsuku | 6400 | 36 | 0.56% |
| ファンキーレイティング | 1560 | 41 | 2.63% |
| ファンキーレイティング | 1485 | 45 | 3.03% |
| 自作ツール | 1688 | 46 | 2.76% |

比較結果
キーワード出現率チェック無料サイトの結果と、ほぼ同じような結果となった。
自作ツールのソースコード
今回生成した自作ツールのプログラムソースコードです。
参考にしてみてください。
【自作ツールのプログラムソースコード(C言語)】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#include <mecab.h>
typedef struct WordNode {
char *word;
int count;
double percentage;
struct WordNode *next;
} WordNode;
const char *EXCLUDE_LIST[] = {
",", ",", ".", "。", "、", "!", "!", "?", "?", ":", ":", ";", ";", "(", ")", "(", ")",
"\"", "“", "”", "'", "‘", "’", "-", "ー", "~", "[", "]", "{", "}", "「", "」", "『", "』", "【", "】",
"と", "が", "に", "の", "は", "を", "で", "や", "から", "まで", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"あ", "い", "う", "え", "お", "か", "き", "く", "け", "こ", "さ", "し", "す", "せ", "そ",
"た", "ち", "つ", "て", "と", "な", "に", "ぬ", "ね", "の",
"は", "ひ", "ふ", "へ", "ほ", "ま", "み", "む", "め", "も", "や", "ゆ", "よ", "ら", "り", "る", "れ", "ろ", "わ", "を", "ん",
"が", "ぎ", "ぐ", "げ", "ご", "ざ", "じ", "ず", "ぜ", "ぞ", "だ", "ぢ", "づ", "で", "ど", "ば", "び", "ぶ", "べ", "ぼ",
"、", "。", ",", ".", "・", ":", ";", "?", "!", "゛", "゜", "´", "`", "¨",
"^", "  ̄", "_", "ヽ", "ヾ", "ゝ", "ゞ", "〃", "仝", "々", "〆", "〇", "ー", "―", "‐", "/",
"\", "~", "∥", "|", "…", "‥", "‘", "’", "“", "”", "(", ")", "〔", "〕", "[", "]",
"{", "}", "〈", "〉", "《", "》", "「", "」", "『", "』", "【", "】", "+", "-", "±", "×",
"÷", "=","≠","<",">","≦","≧","∞","∴","♂","♀","°","′","″","℃","¥", "/",
"$", "¢", "£", "%", "#", "&", "*", "@", "§", "☆", "★", "○", "●", "◎", "◇",
"◆", "□", "■", "△", "▲", "▽", "▼", "※", "〒", "→", "←", "↑", "↓", " ", " ", "\n", "\r", NULL
};
int is_excluded_word(const char *word) {
if (strlen(word) == 0) return 1;
for (int i = 0; EXCLUDE_LIST[i] != NULL; i++) {
if (strcmp(word, EXCLUDE_LIST[i]) == 0) {
return 1;
}
}
for (int i = 0; word[i] != '\0'; i++) {
if (isdigit((unsigned char)word[i])) {
return 1;
}
}
if ((strlen(word) == 1) && ((word[0] >= 0x3040 && word[0] <= 0x309F) || (word[0] >= 0x30A0 && word[0] <= 0x30FF))) {
return 1;
}
return 0;
}
WordNode *add_or_increment_word(WordNode *head, const char *word) {
if (is_excluded_word(word)) {
return head;
}
WordNode *current = head;
while (current != NULL) {
if (strcmp(current->word, word) == 0) {
current->count++;
return head;
}
current = current->next;
}
WordNode *new_node = (WordNode *)malloc(sizeof(WordNode));
new_node->word = strdup(word);
new_node->count = 1;
new_node->percentage = 0.0;
new_node->next = head;
return new_node;
}
void free_word_list(WordNode *head) {
WordNode *current = head;
while (current != NULL) {
WordNode *next = current->next;
free(current->word);
free(current);
current = next;
}
}
int count_specific_word_in_text(const char *text, const char *word) {
int count = 0;
const char *temp = text;
while ((temp = strstr(temp, word)) != NULL) {
count++;
temp += strlen(word);
}
return count;
}
int compare_words(const void *a, const void *b) {
WordNode *wordA = *(WordNode **)a;
WordNode *wordB = *(WordNode **)b;
return wordB->count - wordA->count;
}
void calculate_percentages(WordNode *head, int total_words) {
WordNode *current = head;
while (current != NULL) {
current->percentage = ((double)current->count / total_words) * 100;
current = current->next;
}
}
void print_word_list_to_csv(FILE *csv_file, WordNode **word_array, int word_count, int total_words) {
fprintf(csv_file, "\xEF\xBB\xBF"); // BOMの追加
fprintf(csv_file, "Word,Count,Percentage\n");
for (int i = 0; i < word_count; i++) {
fprintf(csv_file, "%s,%d,%.2f%%\n", word_array[i]->word, word_array[i]->count, word_array[i]->percentage);
}
fprintf(csv_file, "Total Words,%d\n", total_words);
}
void print_specific_words_to_csv(FILE *csv_file, const char **search_words, int search_word_count, const char *buffer, int total_words) {
for (int i = 0; i < search_word_count; i++) {
if (search_words[i] != NULL) {
int specific_word_count = count_specific_word_in_text(buffer, search_words[i]);
double percentage = ((double)specific_word_count / total_words) * 100;
fprintf(csv_file, "%s,%d,%.2f%%\n", search_words[i], specific_word_count, percentage);
}
}
}
int main(int argc, char **argv) {
if (argc < 3 || argc > 6) {
fprintf(stderr, "Usage: %s <input file> <output file> <word1> <word2> <word3>\n", argv[0]);
return 1;
}
const char *input_filename = argv[1];
const char *output_filename = argv[2];
const char *search_words[3] = { NULL, NULL, NULL };
for (int i = 3; i < argc; i++) {
search_words[i - 3] = argv[i];
}
FILE *fp = fopen(input_filename, "r");
if (fp == NULL) {
perror("fopen");
return 1;
}
fseek(fp, 0, SEEK_END);
long length = ftell(fp);
fseek(fp, 0, SEEK_SET);
char *buffer = (char *)malloc(length + 1);
fread(buffer, 1, length, fp);
buffer[length] = '\0';
fclose(fp);
int total_characters = strlen(buffer); // Count total characters
mecab_t *mecab = mecab_new2("-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd");
if (mecab == NULL) {
fprintf(stderr, "error in mecab_new2\n");
return 1;
}
const mecab_node_t *node = mecab_sparse_tonode(mecab, buffer);
if (node == NULL) {
fprintf(stderr, "error in mecab_sparse_tonode\n");
mecab_destroy(mecab);
return 1;
}
int total_words = 0;
WordNode *word_list = NULL;
for (; node; node = node->next) {
if (node->stat == MECAB_BOS_NODE || node->stat == MECAB_EOS_NODE) {
continue;
}
char surface[1024];
strncpy(surface, node->surface, node->length);
surface[node->length] = '\0';
if (!is_excluded_word(surface)) {
word_list = add_or_increment_word(word_list, surface);
total_words++;
}
}
calculate_percentages(word_list, total_words);
int word_count = 0;
WordNode *current = word_list;
while (current != NULL) {
word_count++;
current = current->next;
}
WordNode **word_array = (WordNode **)malloc(word_count * sizeof(WordNode *));
current = word_list;
for (int i = 0; i < word_count; i++) {
word_array[i] = current;
current = current->next;
}
qsort(word_array, word_count, sizeof(WordNode *), compare_words);
FILE *csv_file = fopen(output_filename, "w");
if (csv_file == NULL) {
perror("fopen");
return 1;
}
print_word_list_to_csv(csv_file, word_array, word_count, total_words);
print_specific_words_to_csv(csv_file, search_words, 3, buffer, total_words);
//Output total characters count to the CSV file
fprintf(csv_file, "Total Characters,%d\n", total_characters);
fclose(csv_file);
free(word_array);
free_word_list(word_list);
mecab_destroy(mecab);
free(buffer);
return 0;
}

自作ツールのご利用にあたって
プログラムのコンパイル方法
本記事のソースコードのコンパイル方法は以下の通りです。
ファイル例
・ソースファイル:scan_kwd.c
・出力ファイル:scan_kwd
-lオプションで、mecabライブラリを指定します。
プログラムの実行方法
プログラムの実行方法は以下の通りです。
ファイル例
・入力ファイル:input.txt
・出力ファイル:output.csv
・調査キーワード1:キーワード1
・調査キーワード2:キーワード2
・調査キーワード3:キーワード3
ツールご利用にあたって
本ツールを使用する場合、入力する記事を一旦テキストファイルに出力する必要があります。
記事をブラウザで表示させて、全体を選択しコピペしてテキストファイルに保存して使用してください。
競合サイトのページもコピペできれば、競合サイトのキーワード出現率もチェックできます。
本プログラムのご利用は、自己責任でお願いします。
当サイトでは一切の責任を負いません。
\初心者向けSEOツールの記事はこちらから/
-

-
COMPASSをおすすめする5つの理由
続きを見る



{kind=link}